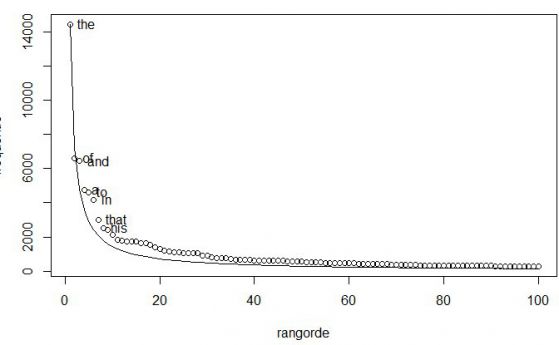


Знаете ли, че във всеки език най-често срещаната дума се появява два пъти по-често, отколкото втората най-използвана дума, 4 пъти по-често от четвъртата, 10 пъти по-често от десетата и така нататък ? Това явление се нарича "закон на Зиф", който е на повече от един век, но досега учените не можеха да разберат защо се случва точно така.
Сандър Лестрейд (Sander Lestrade), лингвист в Университета Радбауд (Radboud University) в Холандия, предлага ново обяснение на този основен закон в компютърната лингвистика в PLoS ONE.
Законът на Зиф описва как честотата на една дума в един естествен език зависи от мястото в рейтинга по честота на използването на думата. Така че най-честата дума се среща два пъти по-често, отколкото е втората най-използвана дума, три пъти толкова често, колкото следващата дума и така нататък, докато се стигне до най-малко използваната дума (вж графиката горе). Законът е кръстен на американския лингвист Джордж Кингсли Зиф (George Kingsley Zipf), който е първият, който се опитва да го обясни през 1935 г., разказва phys.org.
Най-голямата мистерия в компютърната лингвистика
"Мисля, че може да се каже, че Законът на Зиф е най-голямата мистерия в компютърната лингвистика", коментира Сандър Лестрейд. "Въпреки десетилетията теоретизиране, произходът му остават неуловим".
В новото изследване Лестрейд показва, че тази статистическа закономерност може да се обясни с взаимодействието между структурата на изречението (синтаксис) и значението на думите (семантиката) в текста.
С помощта на компютърни симулации той показва, че нито само синтаксисът или само семантиката са достатъчнида предизвикат разпределението по Зиф, но комбинирани тяхното присъствие води до Закона на Зиф.
"В английския език, но също така и в холандския, има само три думи за членуване и десетки хиляди съществителни", обяснява Лестрейд. "Тъй като използваме един член преди почти всяко съществително, членовете се появяват много по-често, отколкото съществителните". Но това не е достатъчно, за да се обясни Закона на Зиф.
"Съществителните също силно се различават помежду си. Думата "нещо", например, е много по-често срещана, отколкото "подводница" и по този начин може да се използва по-често. Но за да се случва често, една дума не трябва да бъде с твърде общ смисъл. Ако се обединят разликите в смисъла между думите в рамките на една част от речта с необходимостта от всяка дума от тази част от речта, ще се разкрие великолепно разпределение по Зиф. И това разпределение ще се различава малко от идеалната крива на Зиф, точно както е в естествения език и както може да види на фигура 1".
Силните страни на новата теория са, че тя не само се съгласува с явленията, срещащи се в естествения език, но и че се отнася и за почти всеки език в света, не само за английския или холандския. Независимо от това е необходимо независимо потвърждение на теорията от други лингвисти.
През последните години се изказаха няколко хипотези за произхода на закона на Зиф и някои от тях се опитаха да го обяснят чисто статистически, като твърдяха, че дори случайни текстове възпроизвеждат този модел.
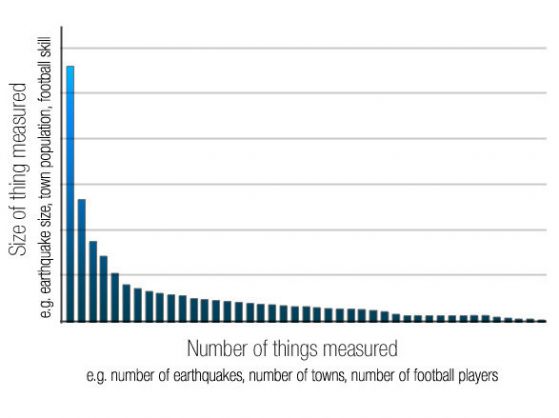
Интересно е, че Законът на Зиф се проявява в много други класации, които не са свързани с езика, като населението на градове в различни страни, размерите на корпорации, класации на доходите, броя на хората, които гледат телевизионен канал и така нататък.
Джордж Зиф през 1949 г. за пръв път показва, че разпределението на доходите на хората е според техния номер в класацията по доходи: най-богатият човек има два пъти повече пари от следващия по богатство човек и така нататък. Това твърдение се оказа вярно за няколко държави (Англия, Франция, Дания, Холандия, Финландия, Германия, САЩ) в периода от 1926 до 1936 г.
Този закон е верен и за разпределянето на градовете по население: градът с най-много население във всяка страна има два пъти повече хора от следващия по големина град, и така нататък. Ако подредите всички градове на някоя страна в списъка с низходящ ред на числеността на населението, а на всеки град се определи ранг, тоест номер в класацията. Тогава числеността на населението и рангът се подчиняват на простата закономерност, изразена с формулата:
PN = P1 / п
където PN е населението на града с п-ти ранг; P1 е населението на града с най-много население в страната (1-ви ранг).
Закона на Зиф e математически описан от разпределението на Парето от теорията на вероятностите.
За съжаление не намерихме данни от мащабно научно изследване за най-често срещамите думи в българския език.
попаднаме на самостоятелно проучване на програмиста Николай Костов на базата на статии в българската Wikipedia.
Анализирани са 220681 статии, в тях са намерени общо 46707608 думи, съдържащи само български букви, от които думи 714876 са различни. Данните са актуални към 20-ти август 2011 г. Трите най-често срещани думи са „на“, „и“ и „в“.
Ето данните, които се отклоняват от Закона на Зиф заради спецификата на самата Wikipedia.
на => 2299352 пъти
и => 1228974 пъти
в => 1155405 пъти
потребител => 972950 пъти
е => 843001 пъти
от => 771623 пъти
за => 541691 пъти
се => 534455 пъти
пр => 502970 пъти
беседа => 488892 пъти
Секцията по компютърна лингвистика към БАН показва най-често срещаните десет български съществителни от масив от 35 000 000 думи. Те са: време, година, нещо, път, час, страна, ден, хора, място, човек.
Още по темата

Човекът
3 златни, 1 сребърен, 3 бронзови медали и почетна грамота на олимпиадата по лингвистика
")
Математика
Колко красива може да е математиката (интервю с Владимир Сотиров)

Човекът
На 2 септември е роден бащата на теорията на катастрофите - Рене Том
















")


Коментари
Моля, регистрирайте се от TУК!
Ако вече имате регистрация, натиснете ТУК!
Няма коментари към тази новина !
Последни коментари
dolivo
Земната ябълка: стара култура за новите климатични времена
dolivo
Земята потъмнява. Какво означава тази тревожна климатична тенденция за бъдещето?
Nikor
На 30 септември 1928 е открит пеницилинът
Прост Човек
Ново обяснение за гигантските експлодиращи кратери в Сибир