

Изкуственият интелект (Artificial Intelligence - AI) и машинното самообучение (Machine Learning - ML) са едни от най-горещите теми в момента.
Терминът "AI" се използва всеки ден, но доста често не се разбира какво е изкуствен интелект. В статия на Раду Райчеа (Radu Raicea) изданието Medium излага основите на AI и ML, един вид популярно ръководство на тази тема, като най-важната част е какво представлява "Дълбокото самообучение" (Deep Learning), най-популярният тип ML.
Първата стъпка към разбирането за това, как работи "Дълбокото самообучение", е да се разберат разликите между тези два важни термина - AI и ML.
Изкуствен интелект или Машинно самообучение
Изкуственият интелект е имитация на човешката интелигентност в компютрите.
Когато стартираха изследванията на AI, учените се опитваха да възпроизведат човешкия интелект за конкретни задачи - като игра. Те въведоха огромен брой правила, с които компютърът трябваше да се съобрази. Компютърът имаше конкретен списък на възможните действия и вземаше решения въз основа на тези правила.
Машинното самообучение се отнася до способността на дадена машина да се научи да използва големи набори от данни вместо твърди кодирани правила.
ML позволява на компютрите да се учат сами. Този тип самообучение се възползва от мощността на процесорите на съвременните компютри, които лесно могат да обработват големи набори от данни.
Обучение с учител и обучение без учител
Обучение с учител (Supervised Learning) включва използването на етикетирани набори от данни, които имат входове и очаквани резултати.
Когато обучавате AI, използвайки обучение с учител, му давате вход и му казвате очаквания резултат (изход).
Ако резултатът, генериран от AI, е неправилен, трябва да се пренастроят изчисленията му. Този процес се извършва итеративно върху набора от данни, докато AI спре да прави повече грешки.
Пример за обучение с учител е AI, прогнозиращ времето. Той се научава да предсказва времето, използвайки исторически данни. Данните за самообучението имат входове (налягане, влажност, скорост на вятъра) и изходи (температура).
Обучение без учител (Unsupervised Learning) е задача от машинното самообучение като се използват набори от данни без определена структура.
Когато тренирате AI, използвайки обучение без учител, вие позволявате на AI да направи логически класификации на данните.
Пример за обучение без учител е AI, предсказващ вероятното поведение на уеб сайт за електронна търговия. Той няма да се учи, като използва набор от данни за вход и изход. Вместо това ще създаде собствена класификация на входните данни. Той ще ви каже кой тип потребители е най-вероятно да купуват различни продукти.
И така, как работи дълбокото самообучение?
Дълбокото самообучение (Deep Learning) е метод за машинно самообучение. То ни позволява да тренираме AI за прогнозиране на резултатите, като има предвид набор от входни данни. Както обучението с учител и обучението без учител може да се използва за самообучение на AI.
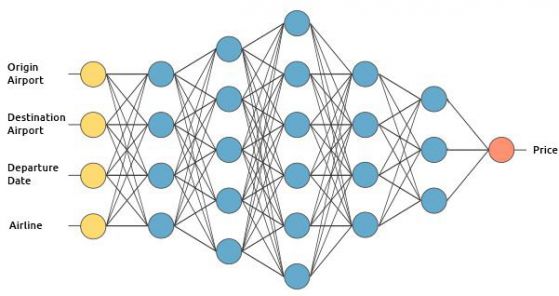
Ще научим как работи дълбокото самообучение чрез изграждането на хипотетична услуга за оценка на цената на билета. Ще го обучим, като използваме контролиран метод на самообучение.
Ние искаме нашият "оценител на цената на самолетния билет" да предскаже цената като използва следните входни данни (изключваме връщането на билети за простота):
- Летище, от което се излита
- Летище - дестинация
- Дата на заминаване
- Авиолиния
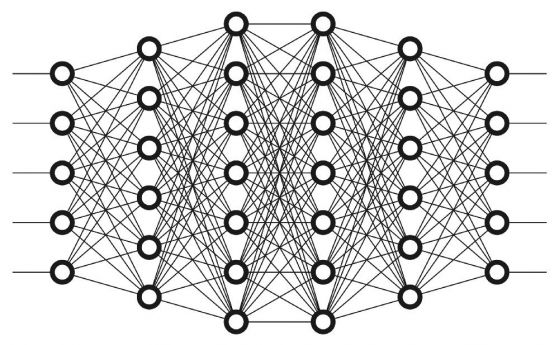
Невронни мрежи
Нека да погледнем отвътре в мозъка на нашия AI.
Подобно на животните, мозъкът на нашия AI-оценител има неврони.
Те са представени с кръгчета. Тези неврони са взаимосвързани.
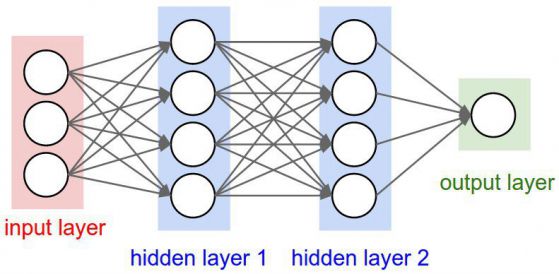
Схема: CS231n
Невроните се групират в три различни типа слоеве:
- Входен слой
- Скрити слоеве
- Изходен слой
Входният слой получава входни данни. В нашия случай има четири неврони във входния слой: летище, от което се излита, летище - дестинация, дата на заминаване и авиокомпания. Входният слой предава входните данни в първия скрит слой.
Скритите слоеве изпълняват математически изчисления на базата на входните данни. Едно от предизвикателствата при създаването на невронни мрежи е определянето на броя на скритите слоеве, както и броя на невроните за всеки слой.
"Дълбокото" в дълбокото самообучение означава, че има повече от един скрит слой.
Изходният слой връща изходните данни. В нашия случай той ни дава прогнозната цена.
Как се изчислява прогнозната цена?
Тук е мястото, където започва магията на дълбокото самообучение. Всяка връзка между невроните се асоциира с някаква тежест. Този коефициент на тежестта диктува важността на входната стойност. Първоначалните коефициенти на тежестта се задават на случаен принцип.
При предсказване на цената на самолетен билет, датата на заминаване е един от най-тежките фактори. Следователно невронните връзки на датата на заминаване ще имат голям коефициент на тежестта.
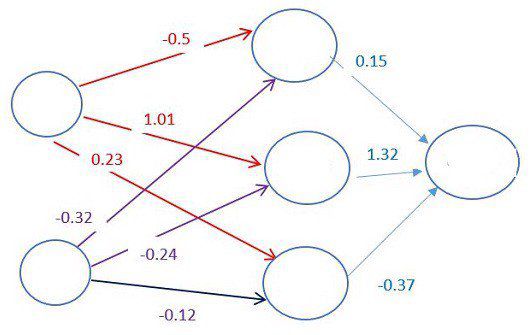
Схема: CodeProject
Всеки неврон има функция на активация (Activation Function). Тези функции са трудни за разбиране без математически разсъждения. Просто казано, една от нейните цели е да "стандартизира" изхода от неврона.
След като наборът от входни данни премине през всички слоеве на невронната мрежа, той връща изходните данни през изходния слой.
Нищо сложно, нали?
Обучение на невронната мрежа
Обучението на AI е най-трудната част от дълбокото самообучение. Защо?
- Нуждаете се от голям набор от данни.
- Нуждаете се от голяма изчислителна мощност.
За нашата оценка на цената на билета трябва да намерим исторически данни за цените на билетите. И поради големия брой възможни комбинации от летища и дата на тръгване, се нуждаем от много голям списък с цените на билетите.
За да обучим AI, трябва да му дадем входните данни от нашия набор данни и да сравним неговите резултати с резултатите от масива от данни. Тъй като AI все още не е обучен, резултатите от него ще бъдат погрешни.
След като преминем през целия набор от данни, можем да създадем функция, която ни показва колко неправилни са резултатите от AI спрямо реалните резултати. Тази функция се нарича функция на грешката.
В идеалния случай искаме нашата функция на грешката да е нула. Това се случва, когато резултатите на нашия AI са същите като резултатите от набора данни.
Как можем да редуцираме функцията на грешката?
Променяме коефициентите на тежестта между невроните. Можем да ги променим на случаен принцип, докато не получим ниска функция на грешката, но това не е много ефективно.
Вместо това ще използваме техника, наречена Gradient Descent (спускане по градиента).
Това е техника, която ни позволява да намерим минимума на функцията. В нашия случай търсим минимума на функцията на грешката.
Тя работи, като променя коефициентите на тежестта на малки стъпки след всяка итерация на набора данни. Чрез изчисляване на градиента на функцията на грешката при определен коефициент на тежестта можем да видим в коя посока е минимумът.
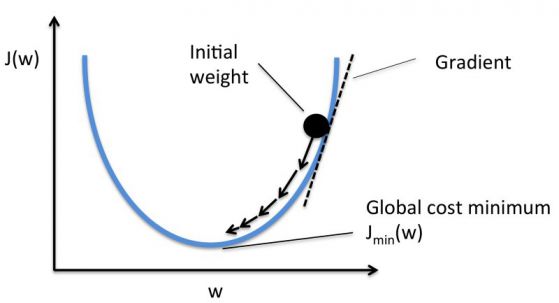
Схема: Sebastian Raschka
За да сведете до минимум функцията на грешката, трябва да минем през итерации (да повторим) няколко пъти набора данни. Ето защо се нуждаете от голяма изчислителна мощност.
Актуализирането на коефициентите на тежестта със спускане по градиента се извършва автоматично. Това е магията на дълбокото самообучение! След като обучихме нашия AI-оценител на самолетни билети, можем да го използваме, за да предвидим бъдещи цени.
Има много други видове невронни мрежи: Конволюционни невронни мрежи (Convolutional Neural Networks) за компютърно зрение (Computer Vision) и циклични невронни мрежи (Recurrent Neural Networks) за обработка на естествен език (Natural Language Processing).
Да обобщим...
- Дълбокото самообучение използва невронна мрежа, за да имитира интелигентността на животните.
- Има три типа слоеве от неврони в невронна мрежа: входен слой, скрити слоеве и изходен слой.
- Връзките между невроните се асоциират с теглови коефициент, диктувайки важността на входната стойност.
- На невроните се прилага функция на активация на данните, за да "се стандартизира" резултатът, излизащ от неврона.
- За да се обучи невронната мрежа, има нужда от голям набор от данни.
- Последователното изчисляване на набора данни и сравняването на резултатите ще помогне да се състави функция на грешката, която да показва колко AI е далеч от реалните резултати.
- След всяка итерация на набора от данни, коефициентите на тежестта между невроните се коригира с помощта на спускане по градиента, за да се редуцира функцията на на грешката.
Още по темата

Космос
Изкуствен интелект открива осма планета около далечна звезда в данни на НАСА

Физика
Българският принос в роботиката – изобретенията на доц. Иван Чавдаров
")
Технологии
Изкуствен интелект създава видео с фалшива реалност, неразличима от истинската (видео)














Коментари
Моля, регистрирайте се от TУК!
Ако вече имате регистрация, натиснете ТУК!
Няма коментари към тази новина !
Последни коментари
Прост Човек
Последната теорема на Стивън Хокинг преобръща времето и причинността
Прост Човек
Разрязването на фотон на две създава безкраен рояк от частици
zlatkov
Учени сканират 74 милиона радиосигнала от междузвезден обект за признаци на извънземни технологии
Джендо Джедев
За срещата на Земята с Халеевата комета през 1910 г. някои са пили "противокометни хапчета"