")

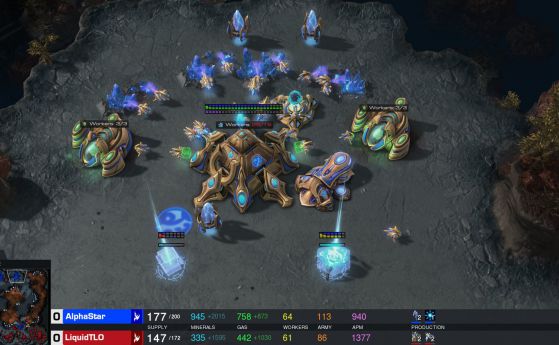
Изкуственият интелект AlphaStar, създаден от DeepMind (собственост на Alphabet Inc.), победи двама професионални играчи в най-предизвикателната игра - стратегия в реално време (RTS) - StarCraft II, съобщава сайтът на компанията.
Срещите се проведоха при условия на професионален мач на състезателна карта и без никакви игрови ограничения.
Срещите на алгоритъма с двама професионални играчи - Дарио Вунш (Dario "TLO" Wünsch) и Гжегож Коминч (Grzegorz "MaNa" Komincz) - се проведоха през декември, но тази седмица, на 24 януари, се проведе последният двубой.
Преди това алгоритмите на DeepMind победиха най-силния играч на Го и прогнозираха формата на протеин много по-добре от професионалните биолози. Но във всеки от тези случаи изкуственият интелект разполагаше с цялата налична информация.
Въпреки че имат значителни успехи във видеоигри като Atari, Mario, Quake III Arena Capture the Flag и Dota 2, досега на AI технологиите им бе трудно да се справят със сложността на StarCraft.
В случая на стратегическа игра в реално време като StarCraft II, всичко е различно - това е игра със скрита информация. Машината не може да предскаже действията на играча, така че трябва да се адаптира към неговите маневри.
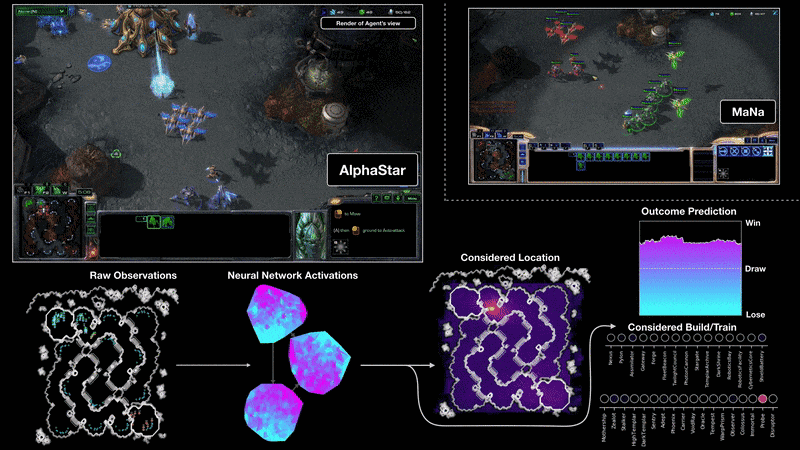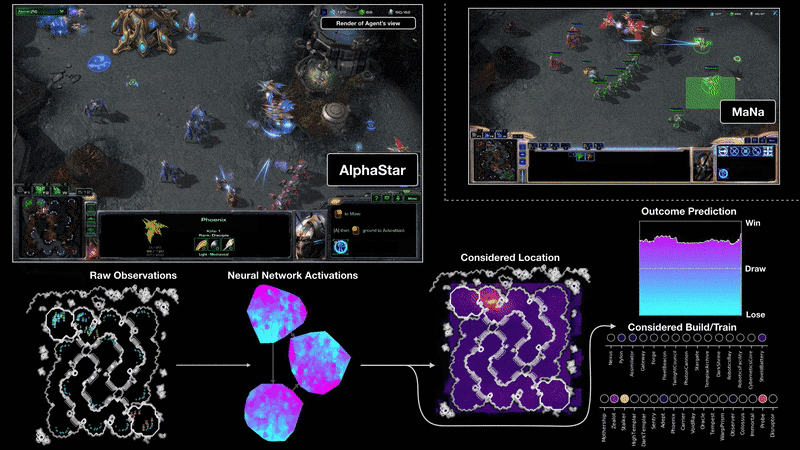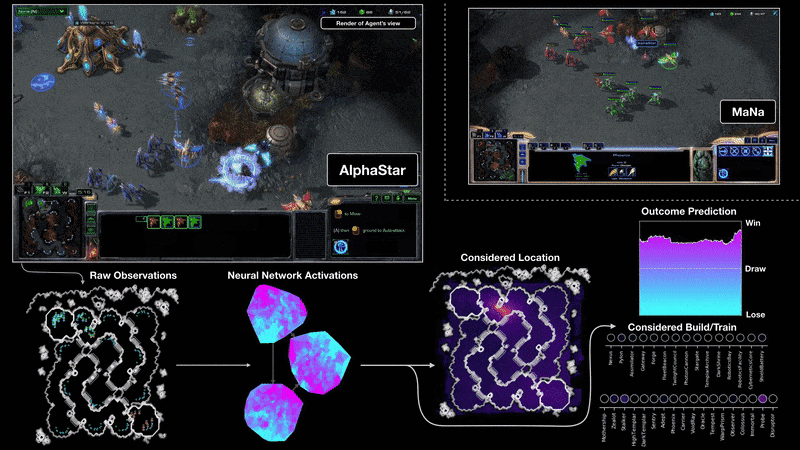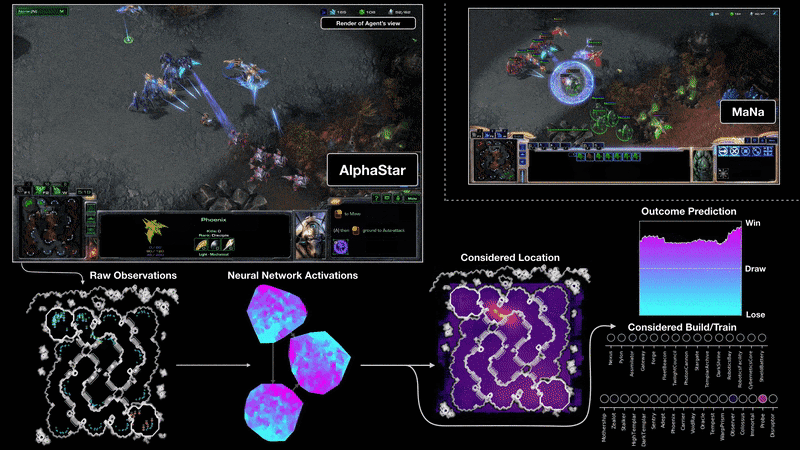
Визуализация на агента на AlphaStar по време на игра 2 в мача срещу MaNa. Показана е играта от гледна точка на агента: суровият вход за наблюдение на невронната мрежа, вътрешните активации на невронната мрежа, някои от разглежданите действия, които агентът може да предприеме, като например къде да кликне и какво да се изгради, и прогнозирания резултат. Погледът на Мана към играта също е показан, въпреки че не е достъпен за агента.
Необходимостта от балансиране на краткосрочните и дългосрочните цели и адаптирането към неочаквани ситуации представлява огромно предизвикателство за системите AI, които често са не толкова гъвкави. Овладяването на този проблем изисква пробиви в няколко изследователски предизвикателства на AI, включително:
- Теория на игрите: StarCraft е игра, в която, както и в "камък, ножица, хартия", няма една най-добра стратегия. Като такъв, процесът на обучение на AI трябва непрекъснато да изследва и разширява границите на стратегическите знания.
- Несъвършена информация: За разлика от игри като шах или Го, където играчите виждат всичко, важната информация е скрита от играча на StarCraft и трябва да бъде откривана активно.
- Дългосрочно планиране: Подобно на много проблеми от реалния свят причинно-следственият ефект не е мигновен. Действията, предприети в началото на играта, може да не се изплатят дълго време.
- Реално време: За разлика от традиционните настолни игри, в които играчите се редуват с ходовете си, играчите на StarCraft трябва да изпълняват действията си непрекъснато, докато трае играта.
- Голямо пространство за действие: Стотици различни единици и сгради трябва да бъдат контролирани наведнъж, в реално време, което води до комбинаторно пространство от възможности. Освен това действията са йерархични и могат да бъдат модифицирани и допълнени.
Благодарение на тези огромни предизвикателства, StarCraft се очертава като „голямо предизвикателство” за изследванията на изкуствения интелект.
Как е обучен AlphaStar
Поведението на AlphaStar се генерира от дълбока невронна мрежа, която получава входни данни от суровия интерфейс на играта (списък на единиците и техните свойства) и извежда последователност от инструкции, които представляват действие в играта.
AlphaStar използва и нов алгоритъм за мултиагентно обучение. Първоначално невронната мрежа бе обучавана от игрите на реални хора, предоставени от компанията - създател на играта Blizzard Entertainment. Това позволи на AlphaStar да научи чрез имитация основните микро и макро стратегии, използвани от играчите на StarCraft. След като усвоява поведенческите модели на играчите, тя се научава да побеждава вградения в играта изкуствен интелект “Elite” в 95% от случаите. Тогава различните й агенти се състезават един с друг в турнир с елиминации. Той се провежда в ускорен режим, така че всеки от тях играе около 200 години.
След като избират най-успешния агент, авторите го поставят срещу TLO и MaNa. Първо той спечели пет от пет мача с TLO, а след това друга версия на невронната мрежа побеждава MaNa същия брой пъти. В същото време алгоритъмът извършва по-малко действия на минута от съперниците си. Това вероятно се дължи на малко предимство, което все так AI притежава. За разлика от човека, той не вижда част от известната карта (екрана), а цялата, така че не трябва да превключва между различните области. Освен това зрителите забелязват, че той може да командва три отряда, разположени в различни зони по едно и също време, което човекът определено не е способен.
")


")
















Коментари
Моля, регистрирайте се от TУК!
Ако вече имате регистрация, натиснете ТУК!
Няма коментари към тази новина !
Последни коментари
Прост Човек
Колко бързо става квантовото вплитане? Учени го изследват в атосекунден мащаб
Прост Човек
Последната теорема на Стивън Хокинг преобръща времето и причинността
Прост Човек
Разрязването на фотон на две създава безкраен рояк от частици
zlatkov
Учени сканират 74 милиона радиосигнала от междузвезден обект за признаци на извънземни технологии