


Научните анализи днес са пълни с математически уравнения, графики и застрашителна терминология. Възможно ли е обаче сложните модели, които се публикуват на сериозни места, да се окажат... без връзка с реалността?
В тази статия можете да видите няколко примера за начините, по които учените биха могли да паднат в пропастта между данните и заключенията. И как сами да не падате в тази пропаст.
Скептикът като chad
Има фирми, наемащи служителите си с тестове за интелигентност или личностни особености. Учени, които разработват алгоритми за машинно обучение, за да предскажат само по формата на лицето дали ще убиеш човек, или развиеш определено психично заболяване. Появяват се метаанализи, обявяващи връзка между това или онова.
Такива примери отразяват все научни идеи със съмнителни последствия за живота на хората и политиките в обществото. Затова и не е изненадващо, че още древните автори търсят методи, с които да противостоим на прекомерната вяра в нещо – независимо ново или старо.
Един хубав непреходен похват (а и не само един) ни се предлага от Секст Емпирик в неговите “Очерци върху скептицизма”. Там той ни предупреждава, че ако опитаме да изберем между две представи, лесно можем да ударим на камък (той избира между: “снегът в действителност е бял” срещу “снегът в действителност е тъмен”).
За да изберем едната представа, ние, разбира се, ще трябва да дадем определено доказателство в нейна подкрепа. Според Секст Емпирик обаче щом дадем това доказателство, ние ще се прецакаме, защото тогава ще трябва да дадем и доказателство, че доказателството е вярно, както и доказателство, че доказателството на доказателството е вярно и тъй до безкрай (Morison, 2019).
Но дори отвъд безкрайния регрес, за да изберем пълноценно един научен модел пред друг, на нас ще ни се наложи да се спуснем по-дълбоко и да разгледаме внимателно как работят самите инструменти, които са използвани за обосноваването му. И ако основата на основата се окаже противоречива, или основата на основата на основата..., то целият модел може да рухне.
Вдъхновен от древната мъдрост на Пироновия скептицизъм, ще ви демонстрирам какво става, като се спуснем до основите зад доста съвременни проучвания.
За да внеса повече прецизност, написах и няколко прости симулации в езика за програмиране R, които можете да видите на графиките.
За врачките и IQ тестовете
Много учени изчисляват в проучванията си корелации, с които да определят колко свързани са две неща. Измислят се например различни тестове, с които хората да проверят способностите си, но за да бъдат валидни тези тестове, те трябва да предсказват нещо в действителния свят.
Да вземем за пример тестовете за интелигентност. Според проучванията IQ-то корелира около 50 процента с образованието, работата и успеха в живота, което се приема за добра зависимост (Richardson & Norgate, 2015).

Получаването на положителна корелация е например: колкото повече карам джипа си, толкова повече народът ме обича. А ако корелацията е отрицателна, значи карането на джипа води до обратното. Корелацията може да бъде от нула до единица. Ако имаме 1 или -1, това значи съвършена корелация. Но ако получим нула, значи между двете неща няма установена връзка и може да има всякакви съчетания.
Популярни гурута и интелектуалци добронамерено прокарват тезата, че хората могат да разберат потенциала си с такива тестове. А общества като МЕНСА канят всяка година българските политици да измерят интелигентността си. Както Чарлз Мъри отбелязва, IQ-то “ще те постави на мястото ти” (Herrnstein & Murray, 2010).
В изследванията, които се цитират убедено, се оказва, че има сериозен препъникамък. И това са самите корелации, използвани от учените. Върху проблемите, свързани с корелацията, ми обърнаха внимание караниците в Twitter на Талеб и някои негови технически анализи.
Връзката на IQ-то с реалността е около 50 процента. Но какво точно може да значи това?
Щом видим пред себе си две квадратчета, повечето от нас с висока сигурност биха сложили трето, за да завършим серията. В този случай IQ тестът ще провери много добре умствената изостаналост, защото най-простият възможен модел са три квадратчета. И ако човек не може да види нещо толкова елементарно, е съмнително, че ще покаже висок успех в училище или на работа. Но от друга страна, решаването на по-заплетена задача с фигури дали може да ни подскаже колко добре бихме се справили с Платоновия “Федон” или със стихове на Шекспир?
Талеб ни предлага кратък експеримент. Даваме тест за интелигентност на 10 000 души и ги проверяваме колко ефективно се справят с някаква дейност. Умрелите хора имат 0 на IQ теста и 0 успех в дейността. Останалите имат коефициент на интелигентност, несвързан с представянето (Taleb, 2019, стр. 8).
Колко ще е фалшивата корелация между IQ-то и успеха в живота?

Отговорът е 38 процента! Махнем ли оранжевата точка (умрелите 2000 човека), корелацията ще изчезне на мига.
Всъщност дори да прочетем, че IQ-то има известна връзка с успехите в живота, можем да получим сходни корелации, стига IQ-то да мери само острите неврологични дефицити (например поради инсулт, генетични заболявания, интоксикация и др.) и да става напълно безполезно отвъд това.
Но разбира се, някой може да отвърне, че учените са наясно с подобна опасност и че все пак са взели необходимите мерки, за да я избегнат в проучванията си.
От друга страна, корелациите страдат от един още по-сериозен проблем. Има множество заплетени модели в научната литература, където авторите проверяват какви ли не връзки между явленията и прогнозират мрежи от зависимости: например когнитивни учени, занимаващи се с моделиране на структурни уравнения. Прецизността на техните модели може да изглежда застрашителна или да ни се струва, че проучванията утвърждават убедително някакъв неинтуитивен извод за мозъка или психиката, докато… не видим корелациите.
Или по-конкретно, докато не разберем как следва да видим техните корелации.
Корелациите обезсмислят с лекота множество научни теории, защото се оказва, че информацията, която се спотайва в корелационния коефициент, се появява едва накрая. Какво се опитвам да кажа: на практика корелацията от 50 процента не е на половината път до съвършената, както някои от тези хора предполагат. А е много по-близо до нулата и пълната липса на зависимост, отколкото до другия край.
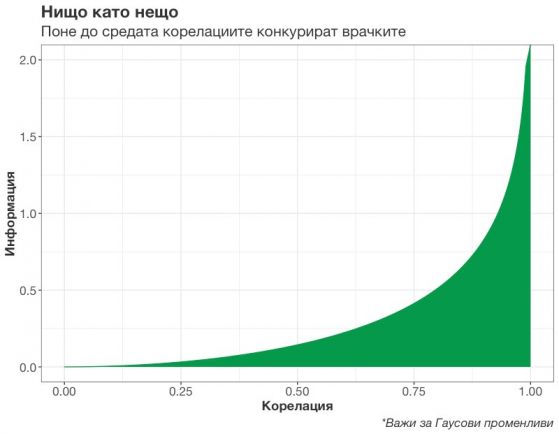
Щом обърнем корелациите в информация, онова, което един тест за интелигентност може да ни каже за успеха в училището, университета или работата, са едва скромните 13 процента или повече от нищото. (Всъщност "13 Ната" - единица за информация - natural unit of information (nat), определя се чрез естествения логаритъм, log2e ≈ 1,443 бита)
И дори да имахме положителна корелация от 80 процента, тя пак щеше да бъде по-близо до нулата, отколкото до 99 процента. Пълната корелация ни гарантира безкрайна и съвършена информация.
Как се изчислява може да видите в допълнението към края на статията. Но ако не ви се четат формули, можете да хвърлите око на следващите няколко графики. Нелинейната информация се изразява в това, че резултатите на хората остават за дълго разпръснати и едва когато имаме много висока корелация, се подреждат рязко в права линия, при която щом едното е високо, и другото е високо.
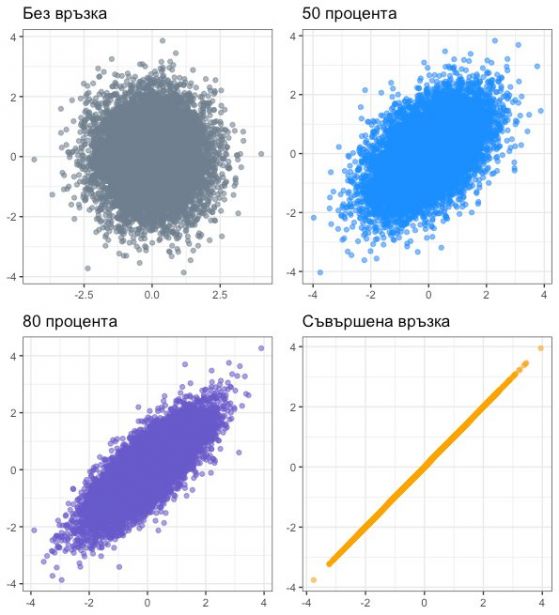
Може да има някаква обща тенденция в част от графиките – по-висок тестов резултат, който в същото време отговаря на по-висок успех в живота, но все пак ключовото е, че хората – отделните точки, се срещат във всякакви съчетания. Някои ще се окажат “високоинтелигентни” хора, които обаче се провалят в работата. Но други, които са със скромни интелектуални резултати, ще отчетат изключително висок успех в ученето или работата. Поне това ни подсказва тълкуването на подобни графики.
Така че когато четете за проучвания или твърдения за “човешката природа”, не гледайте общото положение, а мислете колко разпръснати са хората на практика.
Едно следствие на проблема с информацията е, че в действителност IQ тестовете (или всякакви други подобни тестове) почти не описват хората с наистина високи възможности и постижения.

Когато имаме ниска корелация (разбирай под 90 процента), вероятността да се натъкнем на човек с високо IQ и също толкова голям успех в живота е нищожно по-малка от невиждания случай, при който корелацията е съвършена. За да обхване тестът гениалността… на теб ти трябва корелация над 90 процента! Но в действителност сме много далеч от нея.
Ето как горното изглежда, когато съпоставим всичките връзки със съвършената.

Като съпоставим вероятността за висока интелигентност и висок успех (при несъвършена корелация) спрямо вероятността за същото при висока корелация, ще получим тази графика. Това Талеб нарича Ф пропорция и оттам е единицата на върха на графиката.
Но оставете всичко това. Не е необходимо да сме учили каквато и да е математика, за да видим, че IQ тестовете (и много обобщения за човешката природа) се провалят забележително в предсказването на реалността. При проверката на подобни теории, ежедневният опит може да се окаже доста полезен. Действително наскоро четох в Quora историята на американски студент със средно IQ от 105 и дълга история на учебни затруднения, който завършва с най-висок успех бакалавъра си по математика. Но ако питате някой като Джордан Питърсън, минимумът за успех в математиката или философията са 128 точки и подобни случаи граничат с твърде невероятното.
И разбира се, децата, които не се справят с нещо в училище, са почти сигурно “изправени” пред една неблагоприятна житейска перспектива, защото почитателите на генетичния детерминизъм биха казали, че способностите на човек слабо може да се подобрят с практиката. Което е спорно твърдение (Downes & Matthews, 2020).
Да ловиш престъпници с невронни мрежи
В едни по-прости времена някои учени вярвали, че могат да определят психиката на човек и към какво е предразположен той само по вида на лицето или формата на черепа му. Днес техните теории се обсъждат в университетите като класическа псевдонаука (Gould, 1996). Интересното обаче е, че някои нови изследвания правят опити да предскажат психичните особености на хората от лицето, като използват машинното обучение. И алгоритмите се оказва, че предсказват с поразителна точност.
Според преподавателите по изчислителни методи Джевин Уест и Карл Бергстром обаче изкуственият интелект крие не по-малко капани от добрата стара статистика, които биха могли да вкарат учените (или читателите на някакво проучване) в необосновани интерпретации. В сайта си за “глупостите в света на данните”, те описват казус, при който учени разработват алгоритъм, предсказващ по лицето дали си престъпник (Bergstrom & West, 2020). В тази секция ви представям именно този казус и критиките, формулирани от тях.
През 2016 г. инженерите Сяолин У (Xiaolin Wu) и Си Джан (Xi Zhang) обявяват пред света, че са успели да изградят алгоритъм, който улавя криминалните наклонности с 90 процента точност. Тяхното откритие също така е придружено с твърдението, че компютърният алгоритъм е освободен от множеството заблуди и предубеждения, които замъгляват преценките на хората.
„За разлика от човешкия съдия, един алгоритъм за компютърно зрение или класификатор няма абсолютно никаква субективност, няма емоции, пристрастия поради предишен опит, раса, религия, политическа доктрина, пол, възраст и т.н., не се изморява, не се влияе от лош сън или хранене. Автоматизираното извеждане на престъпността елиминира променливата на метаточността (колко компетентен е човешкият съдия) изцяло"(Wu & Zhang, 2016).
Невероятните твърдения изискват невероятни доказателства, така че да видим къде - според критиците, компютърджиите са оплескали работата.
Ключът към разбирането на проблемите с проучването им са снимките, с които са тренирали невронната мрежа да различава лицата на престъпници от тези на обикновени хора. Предсказанията на мрежата зависят изцяло от нещата, които й се подават, и колко качествени са те.
Авторите събират 1800 снимки на мъже китайци, на възраст между 18 и 55, без отличително лицево окосмяване, белези или татуировки.
Около 1100 от тях са снимки на обикновени хора, събрани из разнообразни сайтове. Но вероятно са взети от професионални сайтове, защото авторите имат информация за професията и образованието на всяко лице.
Около 700 снимки са на престъпници, получени от полицията (лични документи, не от задържането).
Още при събирането на данните вече срещаме достатъчно пропуски, за да поставим под сериозно съмнение получените резултати. Причините, които изникват, са две.
Първата е, че снимките на обикновените хора са взети от сайтове, които вероятно се стремят да създадат добро впечатление за тях или да ги рекламират. Тук лицето има решаваща роля как да се покаже и коя снимка да се избере. Но дори когато образите се избират от други хора, то е пак със същите цели. При снимките от личните документи, от друга страна, има много по-малко свобода или възможност за избор; и никой не се опитва да те направи да изглеждаш привлекателен или свестен.
Вторият проблем е, че учените тренират мрежата със снимки на осъдени престъпници. Така че тук изниква възможността тя просто да улавя особеностите на лицето, правещи по-вероятно съдебните заседатели да сметнат, че си виновен. Ако не си особено привлекателен, това може да натежи срещу теб.
Авторите пишат, че са открили конкретна разлика в структурата на лицето при престъпниците и обикновените хора. Алгоритъмът показва, че престъпниците имат по-кратки разстояния d между вътрешните краища на очите, по-малки ъгли θ между носа и краищата на устата и по-висока извитост р при горната устна.

Това звучи много впечатляващо, но “има удивително просто обяснение за ъгъла θ при носа и устата и извивката p. Когато се усмихваме, крайчетата на устата се отдалечават и горната устна се изправя”.
Така че – Уест и Бергстром подозират – в действителност престъпниците са леко намръщени, докато обикновените хора се усмихват.

В ляво са усреднени снимки на престъпници. В дясно на обикновените хора.
Следователно алгоритъмът изглежда, че не толкова хваща важни разлики в лицевата структура, а просто обикновените хора се усмихват малко повече на снимките си. С оглед на оскъдните данни, дадени от учените, това е едно обосновано предположение.
С други думи, авторите вероятно са допуснали елементарна грешка: объркали са лицевата структура с лицевите изражения. Непреходното с преходното. И зад сложния им дизайн вероятно се крие едно… нищо като нещо.
Заключение
Примерите за нищо като нещо, които обсъдихме в тази статия, показват изключително малка част от злоупотребите с изчислителни методи. Основното при тях обаче е, че дори да прилагаш софистицирани инструменти или модели, техните резултати е вероятно да останат далеч от действителната сложност на човешката природа.
Или както математическият биолог Ричард Левонтин (Lewontin, 2001) отбелязва, “ако посланието на някого е, че нещата са сложни, несигурни и разхвърляни, че нито едно просто правило или сила не могат да обяснят миналото или да предскажат бъдещето на човешкото съществуване, е доста по-трудно да се предаде това послание. Но премерените твърдения за сложността на живота и невежеството ни за детерминантите му не са празни приказки”.
Как получаваме информацията

Цитирани източници
Bergstrom, C., & West, J. D. (2020). Case Studies. Calling Bullshit: The Art of Skepticism in a Data-Driven World. https://www.callingbullshit.org/case_studies.html
Downes, S. M., & Matthews, L. (2020). Heritability. В E. N. Zalta (Ред.), The Stanford Encyclopedia of Philosophy (Spring 2020). Metaphysics Research Lab, Stanford University. https://plato.stanford.edu/archives/spr2020/entries/heredity/
Gould, S. J. (1996). The Mismeasure of Man. Norton.
Herrnstein, R. J., & Murray, C. (2010). The Bell Curve: Intelligence and Class Structure in American Life. Simon and Schuster.
Lewontin, R. C. (2001). The Doctrine of DNA: Biology as Ideology. Penguin.
Morison, B. (2019). Sextus Empiricus. В E. N. Zalta (Ред.), The Stanford Encyclopedia of Philosophy (Fall 2019). Metaphysics Research Lab, Stanford University. https://plato.stanford.edu/archives/fall2019/entries/sextus-empiricus/
Richardson, K., & Norgate, S. H. (2015). Does IQ Really Predict Job Performance? Applied Developmental Science, 19(3), 153–169. https://doi.org/10.1080/10888691.2014.983635
Taleb, N. N. (2019). Fooled by Correlation: Common Misinterpretations in Social „Science“. https://www.academia.edu/39797871/Fooled_by_Correlation_Common_Misinterpretations_in_Social_Science_Wu, X., & Zhang, X. (2016). Automated Inference on Criminality using Face Images. arXiv:1611.04135v1. http://arxiv.org/abs/1611.04135


















 мита за човешкия мозък (видео)")
")
Коментари
Моля, регистрирайте се от TУК!
Ако вече имате регистрация, натиснете ТУК!
Няма коментари към тази новина !
Последни коментари
Прост Човек
Стъклените бутилки съдържат 5 до 50 пъти повече микропластмаси от пластмасовите бутилки
dolivo
Най-старите "човешки" фосили в Япония, се оказаха нечовешки, твърди ново проучване
dolivo
Как „зеленото побутване“ стимулира устойчивите избори на хората
helper68
Натурални суперколайдери: Черните дупки могат да се използват ускорители на частици